
As beginners in machine learning, you will want to have questions answered to common problems. Questions like how to approach, how to start, which algorithm fits best, and so on.
Common problems in machine learning for beginners
Here, we will help you resolve those problems by answering common questions:
Where can you use machine learning?
You can use machine learning for problems when:
- Automation is involved
- Learning from data is needed
- An estimated outcome is required
- Need to understand pattern like user sentiments and developing recommendation systems
- Object required to identify or detect an entity
How to solve machine learning problems?
Here are steps to solve problems in machine learning:
- Read data from JSON and CSV
- Identify dependent and independent variables
- Find out if there are missing values in the data or if it is categorical
- Apply pre-processing data methods if there are missing data to bring it in a go to go format
- Split data in groups for testing and training for concerned purposes
- Spilt data and fit into a suitable model and move on validating the model
- Change parameters in the model if needed and keep up the testing
- An optional step is to switch algorithms to get different answers to the same problem and weigh the accuracies for a better understanding – this explains the accuracy paradox
- Visualize the results to understand where the data is headed and to explain better while representing it
What algorithm should you use?
You need to understand what labelling is to answer this. Labels are the values we need to make an estimate. This represents the Y variable, also known as the dependent variable.
Here is a small example to help you understand this:
if
dependent_variable_exists==True:
supervised learning()
else:
unsupervised learning()
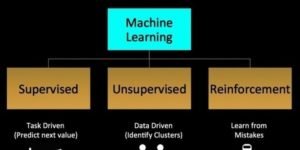 While you’re learning from a machine learning course, you will understand that your supervision and training refers to supervised learning. This means that the results need to be compared by a frame. The frame here is the dependent variable. However, there is no reference for frame under unsupervised learning, which is why the name.
While you’re learning from a machine learning course, you will understand that your supervision and training refers to supervised learning. This means that the results need to be compared by a frame. The frame here is the dependent variable. However, there is no reference for frame under unsupervised learning, which is why the name.
It is time to figure out how algorithms are served. However, it is essential to note that this is a generalized approach. The situations can differ, and so will be the usage of algorithms:
- Numeric data for linear regression
- Logistic regression when the variable is binary
- Multiple category classification through a linear discriminant approach
- Decision Tree, Naive Bayes, KNN, and Ensembles for regression and classification

As you grow in your machine learning career, you will learn how to take random XG boost, forest, Adaboost, among other algorithms for ensembles. You can try these for both regression and classification.
Ensembles, as the name goes, refer to a group of at least two classifiers or regressors. Moreover, it doesn’t matter if it is the same or if working towards the same goals.
Building visualizations
Here are some of the things to remember when visualizing reports:
- You can show class clustering with a scatter plot
- Avoid scatter plot if there are several data points
- Class comparisons can be explained through histogram
- Creating pie charts help comparative breakdown
- Line charts can help analyze reports with frequent deviations like stocks
If a scatter plot has too many data points, it will look clumsy. It will not be a presentable representation to show stakeholders. In such cases, you should use scatter charts.
Final thoughts
These points will help a beginner in machine learning career to become more aware of how to solve problems. You now know the essential things to do and things to avoid to get accurate results.






